最終的なDXAネーション
最終的なDXAネーション' means 'Final DXA Nation' in English.
健康と医学のための縦断的な画像ベースのAIモデル
AIは未来を見ることができる!深層学習による単一および連続した体組成イメージからの全因子死亡率の予測

キーポイント、TLDR:
- 体組成イメージングとメタデータ(例:年齢、性別、握力、歩行速度など)の組み合わせにより、最も優れた10年間の死亡率予測が得られました。
- 縦断的または連続的なモデルは、単一の記録モデルよりも全体的に優れた性能を発揮し、健康データの変化と時間依存性のモデリングの重要性を示しています。
- 縦断的モデルは、より包括的な健康評価を提供する可能性があります。
- 論文を読む
人工知能(AI)と機械学習(ML)は、医療の分野で革命を起こし、精密医療の時代に向かって進んでいます。AIヘルスモデルを開発する動機は、死亡率と疾病を減らし、高品質な生活を延長することです。十分に訓練されたモデルは、提示されたデータをより徹底的に分析する能力を持ち、より包括的な健康評価を提供することができます。
単一の記録と縦断的モデル
画像ベースの医療AI / MLモデルは、しばしば人間のパフォーマンスに匹敵するか、さらに優れたパフォーマンスを発揮し、人間の目には見えにくいパターンや異常を巧みに特定します。ただし、これらのモデルの大部分は依然として単一の時点のデータで動作し、特定の瞬間の健康の孤立したスナップショットを提供します。これらが単一モーダルまたはマルチモーダルモデルであるかにかかわらず、それらは比較的似た時間枠内で収集されたデータを使用して作業し、予測の基礎を形成します。しかし、医療アプリケーションのより広範な文脈では、これらの単一時点モデルは、まさに最初のステップであると言えます。医療AI研究の1つのフロンティアは、人の健康についてのより包括的な見方を提供する縦断的モデルです。
縦断的モデルは、複数の時点からのデータを統合し、単一の瞬間ではなく個人の健康の軌跡を捉えます。これらのモデルは人間の健康の動的な性質にアクセスし、生理学的な変化が常に起こっていることを利用しています。これらの変化を特定の結果や健康上の問題にマッピングできる能力は、予測的なヘルスケアにおいて画期的な変化をもたらす可能性があります。縦断的データの概念は臨床実践では新しいものではありません。これは加齢のモニタリングや虚弱性の予測に定期的に使用されています。骨密度(BMD)の追跡はその典型的な例であり、骨粗鬆症や虚弱性の重要なマーカーです。BMDの定期的な評価により、重要な減少が検出され、潜在的な健康リスクが示唆されます。
縦断的モデルの開発の課題
歴史的に、縦断的モデルの開発にはいくつかの重要な課題がありました。個別の個人ごとに必要な大きなデータ量と計算量以外にも、最も重要な障壁は縦断的な医療データのキュレーションにあります。単一の時点データとは異なり、縦断的データはしばしば複数の医療機関をまたいで患者の健康情報を追跡することを要求します。これには緻密なデータの整理と管理が必要であり、キュレーションプロセスは時間と費用がかかります。多くの成功した研究が縦断的データの収集のために資金援助されています。これらの研究では、長期の観察期間にわたる患者の保持に関する課題が報告されています。したがって、縦断的モデルの開発は、複雑で資源を消費する努力の一環として、依然として困難です。
- 「プリズマーに会いましょう:専門家のアンサンブルを持つオープンソースのビジョン-言語モデル」
- 「アニメート・ア・ストーリー:高品質で構造化されたキャラクター主導のビデオを合成する、検索補完型ビデオ生成によるストーリーテリング手法による出会い」
- ディープネットワークの活性化関数の構築
目標
体組成の変化、筋肉や脂肪組織、骨の比率は死亡率と関連していることが知られています。本研究では、体組成情報を使用して全因子死亡率、つまり人の寿命の予測をより正確に行うことを目指しました。単一の時点データと縦断的データの両方に基づくモデルのパフォーマンスを評価しました。単一の記録モデルでは、死亡率の予測に最も有効な情報のタイプを評価しました。縦断的モデルの開発は、時間の経過とそれが死亡率予測にどのように影響するかを捉えるためのものでした。
データ
この研究のデータは、健康、老化、体組成(Health ABC)研究として知られる、3000人以上の高齢の多人種の男性および女性成人が最大16年間追跡され、モニタリングされたデータから得られました。この研究は、豊富で包括的な長期のデータセットをもたらしました。この研究の一環として、患者は全身の二重エネルギーX線吸収測定(TBDXA)イメージングを受け、いくつかのメタデータが収集されました(表XXXを参照)。モデリングのベストプラクティスに従って、データリークや過剰適合を回避するために、データは70%/10%/20%の割合でトレーニングセット、バリデーションセット、ホールドアウトテストセットに分割されました。
私たちは、体組成を全身の二重エネルギーX線吸収測定(TBDXA)イメージングを使用して量化します。これは長い間、ゴールドスタンダードのイメージングモダリティと考えられてきました。歴史的には、年齢、ボディマス指数(BMI)、握力、歩行速度などの変数を含む患者のメタデータが使用され、老化/死亡を評価し、体組成の代替測定として使用されてきました。患者のメタデータと体組成の代替測定の普及は、DXAスキャナへのアクセスの制限によって推進されました。最近では、スキャンの費用が安くなり、医師の紹介/オーダー/処方箋が不要になり、アクセスの改善が大幅に進んでいます。
シングルイメージモデル
3つのシングルレコードモデルが構築されました。それぞれ異なるデータ入力を使用し、出力はすべて同じもので、10年間の死亡確率でした。最初のモデルは、患者のメタデータのみを使用し、1つの32ユニット、ReLU活性化の隠れ層とシグモイド予測層を持つニューラルネットワークです。2番目のモデルは、TBDXAイメージのみを入力とし、ほとんどの自然画像で見られる3つのカラーチャネル(RGB)ではなく、2つのカラーチャネルを処理するように変更されたDensenet121で構成されています。DXAの二重エネルギー特性により、高エネルギーと低エネルギーのX線イメージが完全に登録され、2つのイメージチャネルにスタックされます。3番目のモデルは、モデル1のメタデータ埋め込みとモデル2のTBDXAイメージ埋め込みを組み合わせ、それを512ユニット、64ユニットの完全接続ReLU層に通し、最後にシグモイド予測層に通します。
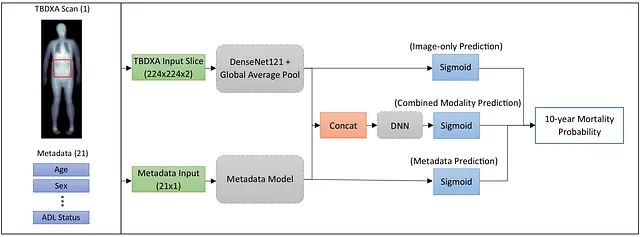
縦断的/時系列モデル
3つの時系列モデルが構築されて評価されました。シングルレコードモデルのアーキテクチャが各時系列モデルの基盤となりましたが、シグモイド予測層は削除され、出力は特徴埋め込みを表すベクトルとなりました。研究の期間中、各患者から複数の時点でデータが収集されました。各時点のデータは、対応する特徴ベクトルを取得するために適切なモデルに入力されました。各患者の特徴ベクトルは順序付けられ、シーケンスにスタックされました。Long Short Term Memory(LSTM)モデルは、特徴ベクトルのシーケンスを取り、10年間の死亡予測を出力するためにトレーニングされました。前述のように、長期の研究を行う際には、保持とデータ収集にいくつかの困難があります。私たちの研究でもこれらの問題はあり、一部の患者は他の患者よりも多くのデータポイントを持っていました。LSTMモデルは、シーケンスのモデリング手法として選択されました。なぜなら、LSTMは各患者に対して同じ入力シーケンス長を使用する必要がないからです。つまり、LSTMはシーケンスの長さが異なるシーケンスで動作することができ、患者が完全なデータポイントセット(約10個)が不足している場合にシーケンスをパディングする必要がなくなります。
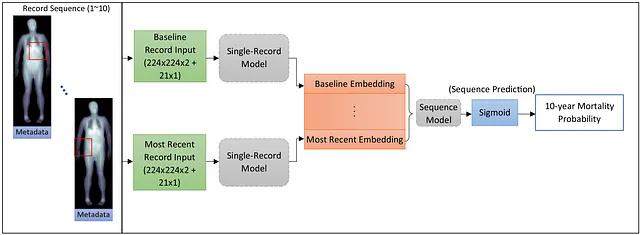
イメージ+メタデータの縦断的モデルが優位
ホールドアウトテストセットでの受信者動作特性(AUROC)の結果から、メタデータはTBDXAイメージのみを使用した場合よりも、シングルレコードモデルと時系列モデルの両方で優れたパフォーマンスを示しました。ただし、メタデータとTBDXAイメージを組み合わせた場合、どちらのモデリングパラダイムでも最も優れたAUROCが得られました。これは、イメージングがメタデータによって捉えられない、死亡予測に有益な情報を提供していることを示しています。これを別の観点で解釈すると、メタデータは体組成を完全に代替するものではなく、死亡予測において体組成の完全な代替測定ではないことを意味します。もしメタデータが完全な代理指標であれば、TBDXAイメージとメタデータを組み合わせてもAUROCに有意な増加や変化はなかったでしょう。組み合わせがより優れたAUROCを示したことは、イメージングがメタデータが捉えられない直交する情報を提供し、イメージングの有用性を更に裏付けています。
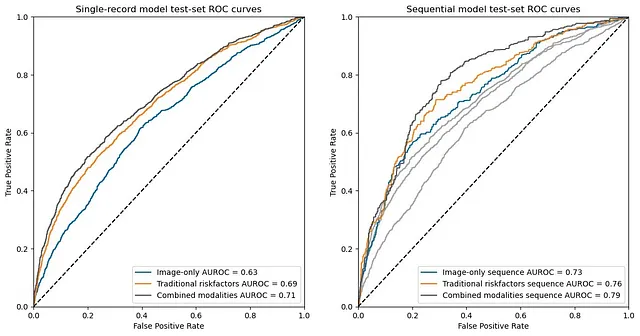
縦断的または連続モデルは、全体的に単一レコードモデルよりも優れたパフォーマンスを示しました。これは、すべてのモデリングアプローチと入力データの種類(メタデータ、画像のみ、メタデータと画像の組み合わせ)にわたって成り立つものです。これらの結果は、変化のモデリングと健康データの時間依存性の重要性を示しています。
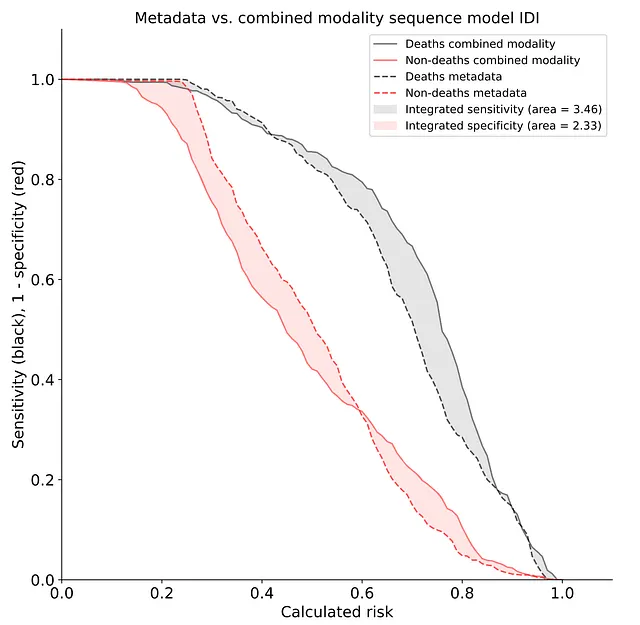
私たちは、画像とメタデータの組み合わせの利点を評価するために、統合差別改善(IDI)分析を実施しました。この分析は、単一レコードモデルを上回る連続モデルで行われました。IDIは5.79であり、統合感度と統合特異度はそれぞれ3.46と2.33でした。これは、画像とメタデータの組み合わせが、次の10年間に生存できない人々を正確に特定するモデルの能力を3.46%向上させ、次の10年間に生存する人々を正確に特定する能力を2.33%向上させることを示しています。全体的に、これはモデルのパフォーマンスの改善率が約5.8%であることを示しています。
では、何が重要なのでしょうか?
私たちの研究は、予測的な医療の領域での連続的なAI/MLモデルの有望な可能性を強調しています。単一レコードモデルと連続モデルの比較分析は、後者の方が優れたパフォーマンスを提供することを明らかにし、健康データ分析における時間の経過による変化のモデリングの重要な役割を示しています。私たちの結果の臨床的な意義には、患者の過去の長期的なデータを考慮に入れるモデルによって、より正確で包括的な健康評価を提供する能力が含まれます。長期的な健康モデルの開発に必要なデータは存在していますが、効率的なデータのキュレーションとこれらのモデルの大規模な開発を可能にする適切なインフラストラクチャと機関のサポートはまだ整っていません。それでも、多くの人々がこれらの障壁を乗り越えるために取り組んでおり、長期的なモデルの開発は医学におけるAIの興味深いフロンティアの一つです。
これらの結果の臨床的な意義は広範囲にわたります。連続モデルは、患者の健康の軌跡についてより正確な個別化された予測を可能にすることで、医療の提供方法を変革する潜在能力を持っています。そのようなモデルは積極的な介入を情報提供し、ケアの結果を向上させ、生命を延ばす可能性さえあります。さらに、メタデータと画像データの両方の使用は、最適な結果のための相乗効果的なアプローチを示す、将来のAI/MLモデルの新たな前例を提供します。これは、患者の健康の正確で包括的な描写をするために、多次元で微妙なデータが必要であることを強調しています。これらの結果は、医療におけるAI/MLの適用において重要な進展を表しており、精密医療の追求におけるエキサイティングな進路を示しています。
詳細情報:
論文を読む
ディープラーニングによる全因子死亡率の縦断的全身DXA画像予測…
死亡率の研究は、全因子死亡率リスクを予測するバイオマーカーを特定しています。これらのマーカーのほとんどは…
www.nature.com
IDIおよび公開された例についての詳細情報:
曲線下面積とそれ以上
医師とデータサイエンティストへ、Pythonコードの例を使ったIDIとNRIの紹介です。AUCだけでは十分ではないかもしれません…
towardsdatascience.com
成分バイオマーカーの検出性向上のための二エネルギー三室乳房画像…
フルフィールドデジタル乳房撮影やデジタル乳房トモシンセシスなどの乳房イメージングは、減少に役立ちました。
www.nature.com
GitHub – LambertLeong/AUC_NRI_IDI_python_functions: さらに便利なカスタムPython関数…
カスタムPython関数を使用して、機械学習モデルや診断テストをさらに分析するためのものです – GitHub…
github.com
曲線下面積(AUC)を超えて、統合された識別改善とネット再分類
医師やデータサイエンティストの方へ、Pythonのコード例を使ったIDIとNRIの紹介です。AUCだけでは十分ではない場合があります…
www.lambertleong.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






