画像分類において、拡散モデルがGANより優れていることがAI研究で明らかになりましたこの研究では、BigBiGANなどの同等の生成的識別的手法に比べて、拡散モデルが分類タスクにおいて優れた性能を発揮することが示されました
拡散モデルはGANよりも優れていることがAI研究で明らかになりましたこの研究によると、拡散モデルは分類タスクで優れた性能を示しています


統一された非教示学習視覚表現の学習は重要でありながらも困難な課題です。多くのコンピュータビジョンの問題は、識別または生成の2つの基本的なカテゴリに分類されます。個々の画像または画像のセクションにラベルを割り当てることができるモデルは、識別表現学習を通じて訓練されます。生成学習を使用する場合、画像を作成または変更し、修復、超解像などの関連する操作を実行するモデルを作成します。統一表現学習者は両方の目標を同時に追求し、最終モデルは識別し、固有の視覚的アーティファクトを作成することができます。このタイプの統一表現学習は困難です。
最初の両方の問題を同時に解決するディープラーニングの手法の1つはBigBiGANです。しかし、より最新の手法の分類および生成のパフォーマンスは、より専門化されたモデルを使用してBigBiGANを上回っています。BigBiGANの主な精度およびFIDの欠点に加えて、エンコーダーによる他の手法と比較してかなり高いトレーニング負荷があり、より遅く、より大きなGANです。 PatchVAEは、VAEのパフォーマンスを認識タスクにおいて改善するために、中間レベルのパッチ学習に集中します。残念ながら、その分類の改善はまだ教示的なアプローチに大きく遅れを取り、画像生成のパフォーマンスも大きく損なわれます。
最近の研究では、監督ありおよび監督なしの両方で生成および分類のパフォーマンスが良い結果を出しています。統一の自己教示学習表現学習は、自己教示画像表現学習の作業の数に比べてまだ探求されている領域です。一部の研究者は、識別モデルと生成モデルは本質的に異なり、それぞれが先行の欠陥のために他方に適した表現ではないと主張しています。生成モデルには、高品質の再構築と作成に低レベルのピクセルおよびテクスチャの特徴を捉える表現が必要です。
- 「新しいAI研究は、3D構造に基づいたタンパク質表現学習のためのシンプルで効果的なエンコーダーを提案する」
- 新しいAI研究が、大規模言語モデル(LLMs)の能力を分析するためのプロンプト中心のアプローチを提案しています
- 清華大学の研究者たちは、メタラーニングの枠組みの下で新しい機械学習アルゴリズムを紹介しました
一方、識別モデルは、特定のピクセル値ではなく、画像の内容の意味に基づいて荒いレベルでオブジェクトを区別するために主に高レベルの情報に依存しています。しかし、彼らは、モデルが低レベルのピクセル情報に対して傾向を持たなければならないが、分類タスクにも優れたモデルを学習するMAEやMAGEのような現在の技術がBigBiGANの初期の成功を支持していると述べています。最新の拡散モデルも生成の目標を達成するのに非常に成功しています。ただし、その分類の可能性はほとんど活用されず、研究されていません。メリーランド大学の研究者は、ゼロから統一表現学習者を作成する代わりに、最先端の拡散モデル、強力な画像生成モデルが既に強力な分類能力を持っていると主張しています。
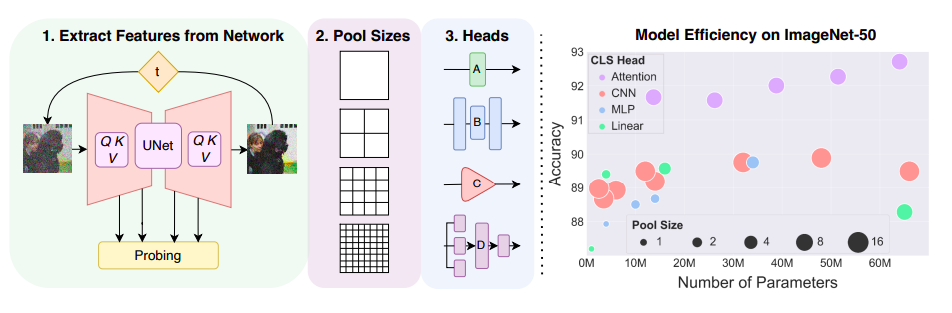
図1は、これら2つの基本的に異なる課題における彼らの素晴らしい成功を示しています。BigBiGANと比較して、拡散モデルを使用した彼らの戦略は、はるかに優れた画像生成性能とより優れた画像分類性能を生み出します。その結果、拡散モデルは、分類と生成の両方を最適化するための最新の統一の自己教示表現学習者に非常に近いことを示しています。拡散モデルでの特徴の選択は、彼らの主な困難の1つです。ノイズステップと特徴ブロックを選択するのは非常に難しいため、彼らはさまざまな側面の適用可能性を調べ、比較します。これらの特徴マップは、チャンネルの深さと空間解像度に関してもかなり大きい場合があります。
彼らはまた、線形分類層を置き換えるためのいくつかの分類ヘッドを提供しており、これにより生成性能を犠牲にすることなく、またはより多くのパラメータを追加することなく分類結果を向上させることができます。彼らは、適切な特徴抽出を伴った優れた分類子として拡散モデルが分類問題に利用できることを示しています。そのため、彼らの手法は任意の事前学習済み拡散モデルに使用することができ、これらのモデルのサイズ、速度、および画像品質の今後の改善によって利益を得ることができます。拡散特徴の転移学習への有効性も検証され、他のアプローチとの特徴の直接比較も行われています。
彼らは、多くのFGVCデータセットにおけるデータの不足を示したため、ファイングレインドビジュアル分類(FGVC)を下流タスクとして選択し、教師なし特徴の使用を求めるものであり、拡散ベースのアプローチはFGVC転移コンテキストで教師なしアプローチを制限するとされる色不変性の種類に依存しないため、特に関連があります。彼らは、ResNetsとViTsからの特徴と比較するために、よく知られた中心化カーネルアラインメント(CKA)を使用して特徴を比較しています。
彼らの貢献は次のとおりです:
• 無条件の画像生成において26.21 FID(BigBiGANに対して-12.37)とImageNet上の線形プロービングにおいて61.95%の精度(BigBiGANに対して+1.15%)を達成し、拡散モデルが統一表現学習として利用できることを示しています。
• 拡散プロセスから最も有用な特徴表現を得るための分析と蒸留のガイドラインを提供しています。
• 分類シナリオでの拡散表現の使用について、アテンションベースのヘッド、CNN、専門のMLPヘッドを標準的な線形プロービングと比較しています。
• さまざまな有名なデータセットを使用して、拡散モデルの転移学習特性をファイングレインドビジュアルカテゴリ化(FGVC)を下流タスクとして検証しています。
• 拡散モデルによって学習された多くの表現を、他のアーキテクチャや事前学習技術、さらには異なるレイヤーや拡散特徴と比較するためにCKAを使用しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- UCサンタクルーズとSamsungの研究者が、ナビゲーションの決定にChatGPTのようなLLM(言語モデル)で共通センスを活用するゼロショットオブジェクトナビゲーションエージェントであるESCを紹介しました
- 新しいAI研究が、転移学習のためのマルチタスクプロンプトチューニング(MPT)を紹介します
- ネゲヴのベン・グリオン大学の研究者たちは、社会的規範の違反を特定するAIシステムを設計しました
- 中国からの新しいAI研究は、機械学習の手法と質問を組み合わせることで、指導者と学生の関係のつながりに新たな次元を明らかにします
- 「人間の知能の解読:スタンフォードの最新のAI研究は、生来の数の感覚は学びのスキルなのか、自然の贈り物なのかを問いかける」
- RLHF(Reinforcement Learning from Human Feedback)において本当に強化学習(RL)は必要ですか?スタンフォード大学の新しい研究では、DPO(Direct Preference Optimization)を提案していますこれは、RLを使用せずに言語モデルを好みに基づいて訓練するためのシンプルなトレーニング方法です
- UCバークレーの研究者たちは、Gorillaという名前の、GPT-4を上回るAPIコールの記述において、Finetuned LLaMAベースのモデルを紹介しました






