小さなオーディオ拡散:クラウドコンピューティングを必要としない波形拡散
小さなオーディオ拡散は、クラウドコンピューティングを必要としない波形拡散です

消費者用のノートパソコンと2GB未満のVRAMを搭載したGPUで音声波形拡散を使用してモデルを訓練し、音を生成する方法の探求
背景
現在、拡散モデルは非常に人気があり、特にStable Diffusionが昨年の夏に世界中で大ブームを巻き起こしました。それ以来、さまざまなコンテキストで無数のバリエーションや新しい拡散モデルが発表されてきました。驚くべき視覚効果が注目を浴びていますが、音響生成と関連する拡散にも重要な進展がありました。
拡散や他の手法によって推進されたジェネレーティブミュージックは、最近多くの成功を収めており、新しいモデルが頻繁に発表されています。OpenAIは2020年にJukeboxの能力で世界を驚かせました。しかし、Googleは今年の初めに非常に注目すべきMusicLMを生み出しました。また、Metaも先月、MusicGenをリリースしてオープンソース化しました。しかし、大手機関だけでなく、独立した研究者たちも参加しており、Riffusion(Forsgren&Martiros)やMoûsai(Schneiderなど)など、非常に興味深い貢献がなされています。これに加えて、過去数年間にはさまざまなモデルがリリースされており、それぞれに利点と欠点があります。
拡散モデルは、その驚くべき創造力の能力から多くの人々を魅了しています。多くの他の機械学習(ML)のジャンルには欠けている何かです。ほとんどのMLモデルは、タスクを実行するために訓練され、成功は正解と不正解で測定されます。しかし、美術や音楽の領域に入ると、どのようにしてモデルを最適化し、最も優れたとされるものにすることができるのでしょうか?もちろん、有名な芸術や音楽を再現することを学習することもできますが、新しさがなければ意味がありません。では、この問題はどのように解決できるのでしょうか?つまり、1と0しか知らない機械に創造性を注入するための方法は何でしょうか?このジレンマに対するエレガントな解決策の1つが拡散です。
拡散 – 一万フィートから
拡散とは、MLにおいて信号からノイズを追加または削除するプロセスのことです(古いテレビのノイズを思い浮かべてください)。前方拡散では信号にノイズが追加され、逆拡散ではノイズが取り除かれます。私たちが最も馴染みのあるプロセスは逆拡散プロセスであり、モデルはノイズを受け取り、それを人間が認識できる形(芸術、音楽、音声など)に「除ノイズ」します。このプロセスはさまざまな方法で操作することができ、さまざまな目的に使用することができます。
- 「トグルスイッチ」は、量子コンピュータがノイズを軽減するのに役立つことができます
- アルゴリズムは、不妊症の男性の精子を医師よりも速く正確に見つけます
- より多くの人々が失明していますAIはそれを戦うのに役立つことができます
拡散における「創造性」は、ノイズを追加することで始まる除ノイズプロセスから生まれます。モデルに毎回異なる出発点を提供して、何らかの形の芸術や音楽に除ノイズすることで、出力が常にユニークであることをシミュレートします。




この除ノイズプロセスをモデルに教える方法は、最初の考えに反して実際には少し直感に反するかもしれません。モデルは実際には逆のこと、つまり、クリーンな信号にノイズを何度も追加することで信号の除ノイズを学習します。アイデアは、モデルが各ステップで追加されるノイズを予測する方法を学習できれば、逆のプロセスで各ステップで取り除かれるノイズも予測できるということです。これを可能にするための重要な要素は、追加/削除されるノイズが定義された確率分布(通常はガウス分布)であることです。これにより、ノイジング/除ノイズのステップが予測可能かつ繰り返し可能となります。
このプロセスにはさらに詳細がありますが、これによって内部で何が起こっているかについての概念的な理解を提供できるはずです。拡散モデル(数理的な定式化、スケジューリング、潜在空間など)についてさらに学びたい場合は、AssemblyAIのブログ記事と以下の論文(DDPM、DDPMの改善、DDIM、安定拡散)をおすすめします。
Tiny Audio Diffusion
機械学習のための音声理解
私の拡散に対する関心は、生成音声において示された潜在能力から来ています。従来、MLアルゴリズムをトレーニングするためには、音声をスペクトログラムに変換しました。スペクトログラムは、時間の経過に伴う音のエネルギーのヒートマップです。これは、スペクトログラム表現が画像に似ており、コンピュータが優れた処理能力を持っているため、生の波形に比べてデータサイズが大幅に削減されるという理由です。
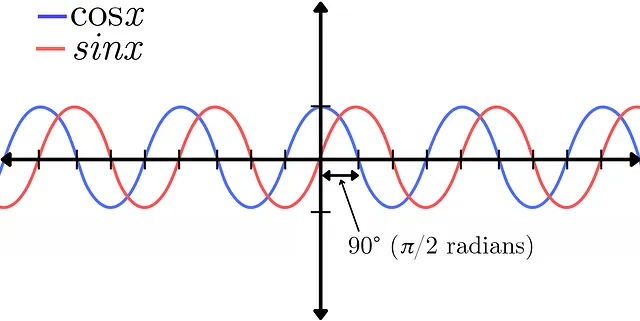
しかし、この変換には解像度の低下や位相情報の喪失などのトレードオフがあります。音声信号の位相は、複数の波形の位置を相対的に表します。これはサイン関数とコサイン関数の違いで示すことができます。これらは振幅に関しては完全に同じ信号を表しており、唯一の違いは二者間の90°(π/2ラジアン)の位相シフトです。位相に関する詳細な説明については、Akash Murthyさんの動画をご覧ください。
位相は、オーディオに従事する人々でさえ理解が難しい概念ですが、音の音質を作り出す上で重要な役割を果たします。言い換えれば、軽々しく捨てるべきではありません。位相情報は、スペクトログラム形式(変換の複素部分)でも表現できます。ただし結果はノイズが多く、視覚的にはランダムに見えるため、モデルが有用な情報を学習するのは困難です。この欠点のため、最近では音声をスペクトログラムに変換せずに生の波形のままモデルをトレーニングすることに関心が寄せられています。これには独自の課題がありますが、振幅情報と位相情報の両方が波形の単一の信号に含まれており、モデルに音の総合的な画像を学習させることができます。
これは波形拡散における私の関心の重要な要素であり、生成音声の高品質な結果をもたらす可能性が示されています。ただし、波形は非常に密な信号であり、人間が聞くことができる周波数範囲を表現するために大量のデータが必要です。たとえば、音楽業界の標準サンプリングレートは44.1kHzです。つまり、モノラルオーディオの1秒を表すには44,100サンプルが必要です。ステレオ再生の場合はその倍です。そのため、ほとんどの波形拡散モデル(潜在的な拡散や他の圧縮手法を利用しないもの)は、トレーニング中にすべての情報を保存するために高いGPU容量(通常は少なくとも16GB以上のVRAM)を必要とします。
動機
多くの人々は高性能で高容量のGPUにアクセスできないか、個人プロジェクトのためにクラウドGPUの利用料金を支払いたくない場合があります。私もこのような状況にありましたが、それでも波形拡散モデルを探求したいと考え、自分のわずかなローカルハードウェア上で動作する波形拡散システムを開発することにしました。
ハードウェアのセットアップ
私は2017年のHP Spectreラップトップを持っており、第8世代のi7プロセッサと2GBのVRAMを搭載したGeForce MX150グラフィックスカードを備えていました。このようなシステムでは、高品質(44.1kHz)のステレオ出力をトレーニングおよび生成できるモデルを作成することを目標としていました。
モデルのアーキテクチャ
このモデルの構築には、Archinetのaudio-diffusion-pytorchライブラリを利用しました。このライブラリの大部分を構築したFlavio Schneider氏に感謝します。
Attention U-Net
ベースモデルのアーキテクチャは、アテンションブロックを備えたU-Netです。これは現代の拡散モデルにおいて標準的なものです。U-Netは、元々画像(2D)セグメンテーションのために開発されたニューラルネットワークですが、波形拡散においてはオーディオ(1D)に適応されています。U-Netのアーキテクチャは、そのU字型のデザインから名前を得ています。
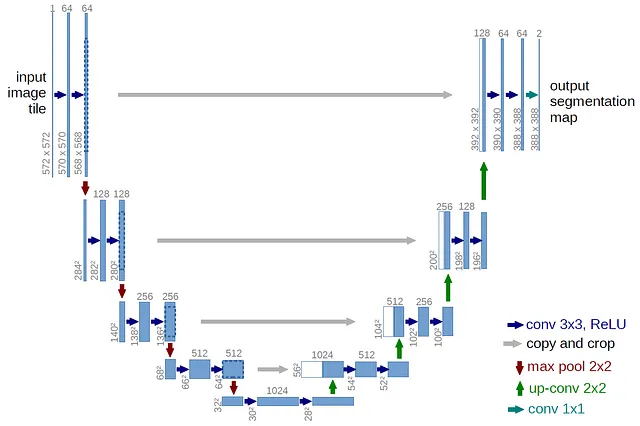
U-Netは、オートエンコーダーに非常に似ており、エンコーダーとデコーダーで構成されています。U-Netには、エンコーダーとデコーダーの対応するレイヤー間に直接接続されるスキップコネクションがあります。これにより、エンコーダーからデコーダーへの細かい詳細の伝達が容易になります。エンコーダーは、入力信号の重要な特徴を捉える役割を担い、デコーダーは新しいオーディオサンプルの生成を担当します。エンコーダーは、入力オーディオの解像度を徐々に低下させ、異なる抽象化レベルで特徴を抽出します。デコーダーはこれらの特徴を取り込み、アップサンプリングして解像度を徐々に高め、最終的なオーディオサンプルを生成します。

このU-Netには、下位レベルにもセルフアテンションブロックが含まれており、出力の時間的な一貫性を維持するのに役立ちます。オーディオが拡散プロセス中のサンプリングの効率を維持し、アテンションブロックの過負荷を避けるために、オーディオを十分にダウンサンプリングすることは重要です。このモデルは、DDIMサンプリングに触発された拡散技術であるV-Diffusionを活用しています。
GPU VRAMの消費を避けるため、ベースモデルのトレーニングに使用するデータの長さを短くする必要がありました。そのため、コンテキストの長さが短い特性を持つワンショットドラムサンプルのトレーニングを行うことにしました。多くの試行錯誤の結果、ベースモデルの長さは、ステレオで32,768サンプル@44.1kHzに設定され、おおよそ0.75秒となりました。これは非常に短いように思われるかもしれませんが、ほとんどのドラムサンプルには十分な時間です。
変換
アテンションブロックのためにオーディオを十分にダウンサンプリングするため、いくつかの前処理変換が試みられました。オーディオデータがモデルのトレーニング前に大幅な情報を失わずにダウンサンプリングできる場合、ノード(ニューロン)とレイヤーの数を増やすことができ、GPUメモリの負荷を増やすことなく最大化することができるという期待がありました。
最初に試みられた変換は、「パッチング」と呼ばれるものでした。元々は画像に提案されたプロセスを、オーディオに適応させたものです。入力オーディオサンプルは、連続する時間ステップごとにグループ化され、チャンクに変換されます。このプロセスは、U-Netの出力時に逆に適用され、オーディオを元の全長に復元します。しかし、チャンク化のプロセスによりエイリアシングの問題が発生し、生成されたオーディオに望ましくない高周波アーティファクトが生じました。
2つ目の試みとして、Schneider氏によって提案された「学習済み変換」というものがあります。これは、U-Netの開始と終了時に大きなカーネルサイズとストライドを持つ単一の畳み込みブロックからなります。複数のカーネルサイズとストライド(16、32、64)を試しましたが、生成されるオーディオにはエイリアシングの問題がありました。ただし、パッチング変換ほど顕著ではありませんでした。
このため、モデルのアーキテクチャを調整して、前処理変換なしで生のオーディオを処理し、十分な品質の出力を生成する必要があると判断しました。
これには、U-Net内のレイヤー数を増やして速やかにダウンサンプリングして重要な特徴を失わないようにする必要がありました。複数の試行錯誤の結果、各レイヤーで2倍のダウンサンプリングが行われるアーキテクチャが最も良い結果を生み出しました。これにより、各レイヤーのノード数を減らす必要がありましたが、最終的には最良の結果が得られました。詳細な情報は、GitHubのtiny-audio-diffusionリポジトリの設定ファイルに記載されています。
結論
事前学習済みモデル
私はキック、スネアドラム、ハイハット、およびパーカッション(すべてのドラム音)を生成するために4つの別々の無条件モデルを訓練しました。訓練に使用したデータセットは、私の音楽制作ワークフローのために収集した小さな無料のワンショットサンプルでした(すべてオープンソース)。より大きく、より多様なデータセットは、各モデルの生成された出力の品質と多様性を向上させるでしょう。モデルは、各データセットのサイズに応じて、さまざまなステップ数とエポック数で訓練されました。
事前学習済みモデルは、Hugging Faceでダウンロードできます。訓練の進捗状況と出力サンプルは、Weights & Biasesでログに記録されています。
結果
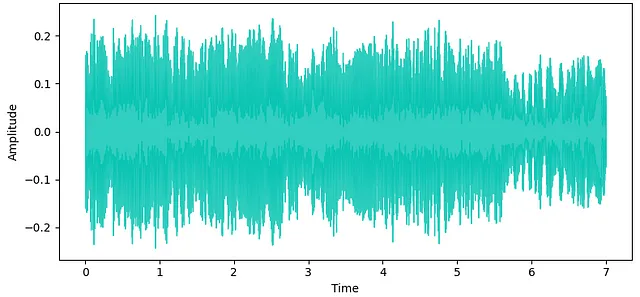
全体的に、モデルのサイズが縮小されているにもかかわらず、出力の品質は非常に高いです。ただし、限られたモデルのサイズのため、わずかな高周波の「ヒス」が残っています。これは、下記の波形に残るわずかなノイズで確認できます。ほとんどの生成されたサンプルは、トランジエントおよび広帯域の音色特性を維持し、クリスプです。モデルは、サンプルの終わりに余分なノイズを追加することがあり、これはおそらくモデルの層とノードの制限の代償です。
モデルからのいくつかの出力サンプルは、こちらで聴くことができます。各モデルからの例示出力は、以下に示されています。
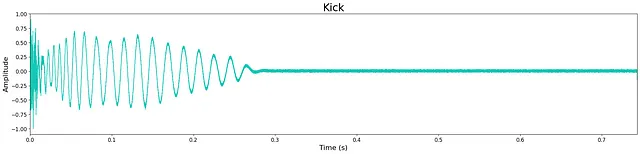
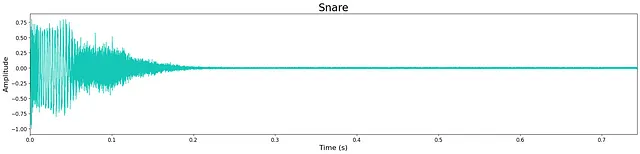
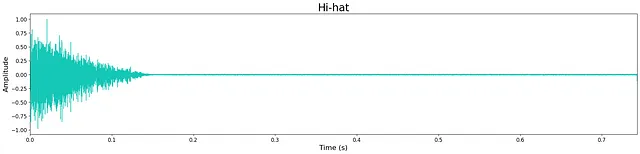
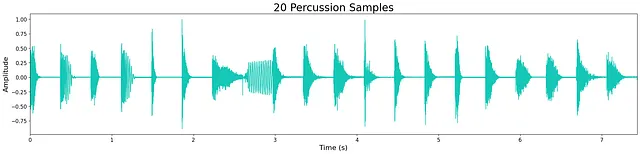
議論
ローカルハードウェア上での波形拡散モデルの探索に加えて、このプロジェクトの重要な目標は、他の人々と同じ機会を共有できるようにすることでした。オーディオ波形拡散を試してみたいがリソースが限られている人々に簡単な入り口を提供したかったのです。そのため、プロジェクトリポジトリを構成して、独自のモデルを訓練または微調整する方法と、Inference.ipynbノートブックから新しいサンプルを生成する手順をステップバイステップで提供しました。
さらに、アナコンダ環境のセットアップ方法と、事前学習済みモデルを使用してユニークなサンプルを生成する方法をデモンストレーションするチュートリアルビデオも録画しました。
拡張的な音声において、波形拡散を含む生成オーディオは、非常に興味深い時代です。このプロジェクトを通じて非常に多くのことを学び、オーディオAIの将来に対する楽観主義をさらに広げることができました。このプロジェクトが、オーディオAIの世界を探求しようとしている他の人々の役に立つことを願っています。
すべての画像は、特に記載がない限り、著者によるものです。
tiny-audio-diffusionのコードはこちらで見つけることができます: https://github.com/crlandsc/tiny-audio-diffusion
tiny-audio-diffusionでサンプルを生成するための環境のセットアップに関するチュートリアルビデオ: https://youtu.be/m6Eh2srtTro
私はAI/MLおよび空間オーディオに特化したオーディオ科学者であり、生涯の音楽家でもあります。もしもっとオーディオAIの応用に興味がある場合は、私の最近の記事であるMusic Demixingをご覧ください。
LinkedInとGitHubで私に会い、現在の仕事と研究について最新情報を得ることができます: www.chrislandschoot.com
After Augustとして、私の音楽はSpotify、Apple Music、YouTube、SoundCloudなどのストリーミングプラットフォームで聴くことができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- (Note Since HTML is a markup language, it doesn’t have a direct translation. The provided text is a translation of the content.)
- 弁護士には、ChatGPTを使用したことについて、許しを求めることを検討するよう命じられました
- ハーバード大学の新しいコンピューターサイエンスの先生は、チャットボットです
- ウィンブルドン、ビデオハイライトの解説にAIを使用
- 非アーベル任意子の世界で初めてのブレードング
- A.I.が建築家に職場デザインの変革をもたらす方法
- サンタクララ大学を卒業した早熟なティーンプロディジー

