大規模な言語モデルにおけるコンテキストに基づく学習アプローチ
大規模な言語モデルの学習アプローチ
推論時にLLMが新しいタスクを学習するためのシンプルで強力なテクニック
はじめに
言語モデリング(LM)は、単語の系列の生成的な尤度をモデル化し、将来の(または欠落している)トークンの確率を予測することを目指しています。言語モデルは、最近の自然言語処理(NLP)の革新となっています。言語モデルのスケールを拡大すること(たとえば、トレーニングの計算、モデルのパラメータなど)は、さまざまな下流のNLPタスクでのパフォーマンスおよびサンプル効率性の向上につながることがよく知られています。調査論文「大規模言語モデルの調査」[1]では、大規模言語モデルのほぼすべての側面をカバーしています。この論文は、LLMについての文献の最新のレビュー、事前トレーニングアプローチに関する詳細、そして最近のRLHFアプローチとのさらなる整合性トレーニングに関する指導の調整技術について詳しく説明しています。指導の調整と整合性の調整のアプローチは、LLMを特定の目標に合わせて適応させるために使用されます。
事前トレーニングまたは適応調整の後、LLMを使用する主なアプローチは、さまざまなタスクを解決するための適切なプロンプト戦略を設計することです。一般的なプロンプトの方法は、インコンテキストラーニング(ICL)とも呼ばれ、タスクの説明やデモンストレーション(例)を自然言語テキストの形式で定式化します。
インコンテキストラーニング
LLMは、コンテキスト中の少数の例から学習するインコンテキストラーニング(ICL)の能力を示しています。多くの研究が示しているように、LLMはICLを通じて数々の複雑なタスクを実行できます。たとえば、数学的な推論問題の解決などです。
インコンテキストラーニングのキーポイントは、類推から学ぶことです。以下の図は、LLMがICLで意思決定を行う方法を示しています。まず、ICLはいくつかの例を使用してデモンストレーションコンテキストを形成する必要があります。これらの例は通常、自然言語のテンプレートで書かれています。次に、ICLはクエリの質問とデモンストレーションコンテキストの一部を連結してプロンプトを形成し、それを言語モデルに与えて予測します[2]。
- Unityは、Museというテキストからビデオゲームを作成するプラットフォームのリリースを発表しましたこのプラットフォームでは、自然言語でテクスチャ、スプライト、アニメーションを作成することができます
- FastSAMとは、最小限の計算負荷で高性能のセグメンテーションを実現する画期的なリアルタイムソリューションです
- もし、口頭および書面によるコミュニケーションが人間の知能を発展させたのであれば… 言語モデルは一体どうなっているのでしょうか?
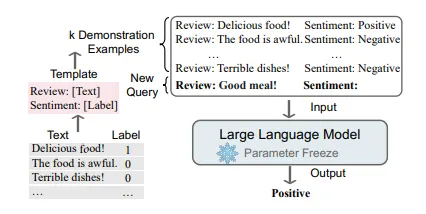
教師あり学習では、モデルパラメータを更新するために逆勾配を使用するトレーニングステージが必要ですが、ICLはパラメータの更新を行わず、事前トレーニングされた言語モデルで直接予測を行います。モデルは、デモンストレーションに隠されたパターンを学習し、適切な予測を行うことが期待されています。
ICLを魅力的にする要素
- 自然言語で書かれた例は、LLMとのコミュニケーションにおける解釈可能なインターフェースを提供します。このパラダイムにより、例やテンプレートを変更することで人間の知識をLLMに取り込むことがはるかに容易になります。
- これは類推から学ぶことにより、人間の意思決定プロセスに類似しています。
- 教師付きトレーニングと比較して、ICLはトレーニングフリーの学習フレームワークです。これにより、モデルを新しいタスクに適応させるための計算コストが大幅に削減されるだけでなく、言語モデルをサービスとして提供することが可能になり、大規模な実世界のタスクに簡単に適用することができます。
では、これはどのように機能するのでしょうか?
事前トレーニング後、LLMは更新されずに興味深いICLの能力(エマージェント能力)を示すことができます[3]。直感的には合理的ですが、ICLの作業メカニズムは不明であり、2つの質問に対して予備的な説明を提供している研究はほとんどありません。
事前トレーニングはICLの能力にどのような影響を与えるのでしょうか?
研究者は、事前トレーニングモデルが大規模なトレーニングステップまたはモデルパラメータを達成すると、いくつかのエマージェントICL能力を獲得すると指摘しています[3]。いくつかの研究では、LLMのパラメータが0.1億から1750億に増加するにつれて、ICL能力も成長することが示されています。研究は、トレーニングタスクの設計がLLMのICL能力に重要な影響を与えると示唆しています。トレーニングタスクに加えて、最近の研究ではICLと事前トレーニングコーパスの関係についても調査されています。ICLのパフォーマンスは、スケールではなく事前トレーニングコーパスのソースに大きく依存することが示されています。
推論中にLLMはどのようにICLを実行するのでしょうか?
論文「なぜGPTはインコンテキストを学べるのか?」[4]では、研究者がトランスフォーマーのアテンションと勾配降下法の間に双対形を見つけ、ICLを暗黙のファインチューニングとして理解することを提案しました。彼らはGPTベースのICLと明示的なファインチューニングを実際のタスクで比較し、ICLが複数の観点からファインチューニングと似た振る舞いをすることを発見しました。このフレームワークの下で、ICLのプロセスは次のように説明できます:順方向計算により、LLMはデモンストレーションに対してメタグラディエントを生成し、アテンションメカニズムを介して暗黙の勾配降下を実行します。
スタンフォードの研究 [5] からの別の視点では、「インコンテキスト学習は暗黙のベイズ推論である」と説明されています。著者たちは、プロンプトを使用して事前学習中に学んだ関連する概念を「特定」し、タスクを実行するためのフレームワークを提供しています。理論的には、これはプロンプトに条件付けられた潜在的な概念のベイズ推論と見なすことができ、この能力は事前学習データの構造(長期の結束性)から来ています。
いくつかの答えがあるにもかかわらず、この研究はまだメカニズムとその根本的な理由をよりよく理解するために進化し続けています。
インコンテキスト学習アプローチ
では、いくつかの人気のあるICLメソッドを探ってみましょう。
- 思考の連鎖(COT)
- 自己整合COT
- 思考の木
思考の連鎖(COT)
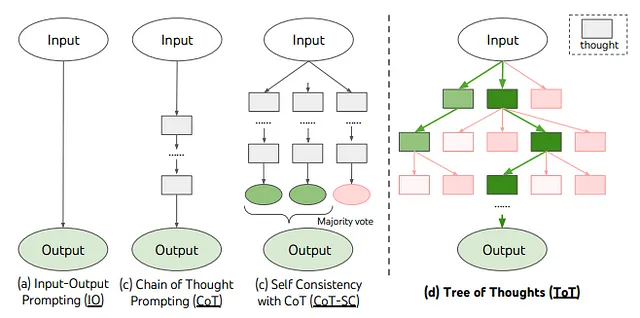
一般的なプロンプト技術(一般的な入出力プロンプトとも呼ばれる)は、算術的推論、常識的推論、および象徴的推論などの複雑な推論タスクにおいてうまく機能しないことが観察されています。COTは、推論を含むノン・トリビアルなケースのパフォーマンスを向上させるための改良されたプロンプト戦略です[6]。ICLのように入力と出力のペアでプロンプトを構築するだけでなく、COTは最終的な出力に至ることができる中間の推論ステップをプロンプトに組み込みます。以下の例からもわかるように。
![参考文献[6]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*D4AEQft-b2VmXb07dIVONg.png)
上記の図は、モデルが誤った答えを出してしまう数学のワード問題を解決するために思考の連鎖を生み出すモデルの例を示しています。左側のICLでは、モデルに数学的な推論の質問の例やデモンストレーション、そして直接の答えが提供されます。しかし、モデルは正しい答えを予測することができません。
右側のCOTでは、モデルは例やデモンストレーションの中間ステップを提供されて、解答にたどり着くのを助けます。同様の推論の質問がモデルに対して行われると、モデルは正しい答えを予測することができるため、COTアプローチの有効性が証明されます。
COTやICLは一般的に、使用例を示すためのいくつかの例を提供し、これを「少数の例(Few-Shot)」と呼びます。また、使用例を示さずに「ステップバイステップで考えましょう」という興味深いプロンプトを提供する別の論文[7]もあり、これを「ゼロショット(Zero-shot)」と呼びます。
「ゼロショットCOT」では、LLMはまず「ステップバイステップで考えましょう」というプロンプトによって推論ステップを生成し、次に「したがって、答えは」というプロンプトによって最終的な答えを導き出します。彼らは、このような戦略がモデルの規模がある一定のサイズを超えた場合には性能を大幅に向上させることを発見しましたが、小規模なモデルでは効果がなく、顕著な能力の進出的なパターンが現れることを示しています。
![参考文献[7]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*l7oj25kVU6ALI5IbBb2BUA.png)
上図: GPT-3の例の入力と出力での (a) 標準の少数の例 (ICL)、(b) 少数の例COT、(c) 標準のゼロショット (ICL)、および (d) 私たちのゼロショットCOT。
少数の例COTと同様に、ゼロショットCOTは複数ステップの推論(青いテキスト)を促進し、標準のプロンプトでは正しい答えに到達できません。少数の例COTと異なり、ゼロショットはどのタスク(算術、象徴的、常識、その他の論理的推論タスク)にも同じ「ステップバイステップで考えましょう」というプロンプトを必要としません。
この研究は、LLMが各質問に答える前に「ステップバイステップで考えましょう」というシンプルなプロンプトを追加することで、ゼロショットの推論能力があることを示しています。
下層で何が起こるか見てみましょう:
ゼロショットCOTは概念的にはシンプルですが、図示されているように推論と答えの両方を抽出するために2回のプロンプトを使用します。
![参考文献[7]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*VvezFJ4L5Ur1he-qT8scAg.png)
このプロセスには2つのステップがあります。まず、「reasoning prompt extraction(推論プロンプトの抽出)」と呼ばれるステップで、言語モデルから完全な推論パスを抽出し、次に2番目の「answer prompt extraction(回答プロンプトの抽出)」を使用して、推論テキストから正しい形式で回答を抽出します。
1番目のプロンプト – 推論の抽出
このステップでは、入力質問xを単純なテンプレート「Q: [X]。A: [T]」を使用してプロンプトx’に変更します。ここで[X]はxの入力スロットであり、[T]は質問xに答えるための思考チェーンを抽出するための手作りのトリガーセンテンスtのスロットです。たとえば、「一つ一つ考えてみましょう」というトリガーセンテンスを使用する場合、プロンプトx’は「Q: [X]。A: 一つ一つ考えてみましょう。」となります。プロンプトされたテキストx’は、言語モデルに供給され、続く文章zを生成します。デコーディング戦略は任意です。
このようなプロンプトの他の例:
論理的に考えてみましょう。
ステップごとに問題を解決してみましょう。
探偵のように一つ一つ考えてみましょう。
答えに入る前に。
2番目のプロンプト – 回答の抽出
2番目のステップでは、生成された文章zとプロンプトされた文章x’を使用して、言語モデルから最終的な回答を抽出します。具体的には、1番目のプロンプトx’のための「[X’] [Z] [A]」:[X’]という形式で3つの要素を単純に連結します。ここで、1番目のプロンプトx’に対して[X’]、最初のステップで生成された文章zに対して[Z]、そして回答を抽出するためのトリガーセンテンス[A]が使われます。このステップのプロンプトは自己拡張されています。なぜなら、プロンプトには同じ言語モデルによって生成された文章zが含まれているからです。実験では、回答の形式に応じてわずかに異なる回答トリガーが使用されます。
たとえば、多肢選択のQAの場合、「したがって、AからEの中で答えは」という表現が使われ、数値の回答が必要な数学の問題の場合、「したがって、答え(アラビア数字)は」という表現が使われます。
この論文[11]には興味深いアイデアや様々なプロンプトのパフォーマンスなどがありますので、詳細はご一読ください。
CoTがLLMに有効なのはいつですか?
CoTは、十分に大きなモデル(通常は10B以上のパラメータを含むモデルなど)にのみポジティブな効果を持ちますが、小さなモデルには効果がありません。この現象は大きな言語モデルの「新たな能力」と呼ばれています。能力が新たなものであるとは、それが小さなモデルには存在せず、大きなモデルにのみ存在する場合を指します[3]。
- これは、算術的な推論、常識的な推論、および象徴的な推論など、ステップバイステップの推論を必要とするタスクの改善に主に効果的です。
- 複雑な推論に依存しない他のタスクでは、標準的な方法よりも性能が低下する場合もあります。興味深いことに、CoTプロンプティングによる性能向上は、標準のプロンプトが不十分な結果をもたらす場合にのみ顕著なものとなるようです。
なぜLLMはCoTの推論を行えるのでしょうか?
- 広く仮説されているのは、それがコードでのトレーニングに起因するものであり、コードでトレーニングされたモデルは強力な推論能力を示すからです。直感的には、コードデータはアルゴリズムの論理とプログラミングフローでうまく組織されており、これはLLMの推論性能の向上に役立つ可能性があります。ただし、この仮説については、公に報告されたコードでのトレーニングの有無を比較する実験の証拠がまだ不足しています。
- CoTプロンプティングと標準的なプロンプティングの主な違いは、最終的な回答の前に推論パスを組み込んでいることです。したがって、一部の研究者は、推論パスのさまざまな要素の効果を調査しています。具体的には、最近の研究では、CoTプロンプティングの中で3つの主要な要素、つまりシンボル(算術推論での数値的な数量)、パターン(算術推論での方程式)およびテキスト(シンボルやパターンではないトークンの残り)を特定しています。後者の2つの部分(つまりパターンとテキスト)がモデルのパフォーマンスに必要不可欠であり、どちらか一方を削除すると著しいパフォーマンスの低下が生じることが示されています。
要約すると、これは研究の活発な分野です。詳しくは、[2]をお読みください。また、トランスフォーマーモデルにおける文脈における学習の可能な理由について考察している興味深い研究[8]もあります。
自己整合COT
COTでは貪欲なデコーディング戦略を使用する代わりに、[9]の著者は貪欲なデコーディング戦略を自己整合と呼ばれる別のデコーディング戦略に置き換えることを提案しています。この戦略は、チェーンオブソートプロンプティングで使用される貪欲なデコーディング戦略よりも言語モデルの推論パフォーマンスを大幅に向上させます。自己整合は、複雑な推論タスクでは通常、正しい答えに到達する複数の推論経路が存在するという直感を活用しています。問題に対して熟考と分析が必要なほど、回答を復元できる推論経路の多様性が増します。
まず、チェーンオブソートプロンプティングで言語モデルにプロンプトを与え、最適な推論経路を貪欲にデコードする代わりに、著者は「サンプルと周辺化」デコーディング手順を提案しています。
以下の図は、例を用いて自己整合法を示しています。
![Reference[9]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*aHxtX5BCVcJ5rHaqB1aHaw.png)
最初に言語モデルのデコーダからサンプルを取り、多様な推論経路のセットを生成します。各推論経路は異なる最終的な回答につながる可能性があります。したがって、サンプルされた推論経路を周辺化して最も一貫性のある回答を最終回答セットから見つけることで、最適な回答を決定します。つまり、モデルのデコーダから回答についての多数決を取ることで、最終回答セットの中で最も「一貫性のある」回答にたどり着きます。
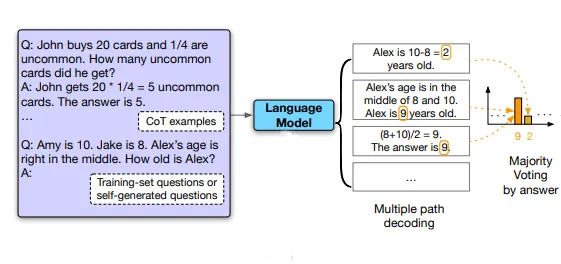
このようなアプローチは、複数の異なる思考方法が同じ回答に至る場合、最終回答が正しいという自信が増すという人間の経験に類似しています。自己整合は、貪欲なデコーディングにおける反復性と局所最適性を回避し、単一のサンプル生成の確率性を緩和します。
幅広い経験的評価により、自己整合はGSM8K(+17.9%)、SVAMP(+11.0%)、AQuA(+12.2%)、StrategyQA(+6.4%)、ARC-challenge(+3.9%)など、一連の人気のある算術および常識的な推論ベンチマークの性能を飛躍的に向上させることが示されています。
自己整合の制限の一つは、より多くの計算コストがかかることです。実際には、性能が迅速に飽和する場合が多いため、人々は少数のパス(例えば5または10)を試して、大きなコストをかけずにほとんどの利益を得ることができます。
思考の木
[10]の著者は、「思考の木」(ToT)というアプローチを提案しています。これは、言語モデルに対する「思考の連鎖」アプローチを一般化し、問題解決に向けた中間ステップとなる一貫したテキストの単位である「思考」を探索することを可能にします。ToTによって、言語モデルは複数の異なる推論経路を考慮し、自己評価の選択肢を検討して次の行動を決定することができます。必要に応じて先を見越したり、グローバルな選択肢を行ったりするためのバックトラッキングも行うことができます。実験結果は、ToTが非自明な計画や検索が必要な3つの新しいタスク(Game of 24、Creative Writing、Mini Crosswords)において、言語モデルの問題解決能力を大幅に向上させることを示しています。
思考の木(ToT)は、思考(上記の図の各長方形ボックス)を介して複数の推論経路を探索することを可能にします。ToTは、ツリー上の探索として問題をフレーム化します。各ノードは、入力xとこれまでの思考のシーケンスziを持つ部分的な解s = [x, z1···i]を表します。ToTでは、思考の分解、思考の生成、状態評価、および探索アルゴリズムの4つの機能があります。
1. 思考の分解: 中間プロセスを思考ステップに分解します:
CoTは明示的な分解なしで思考をサンプルし、ToTは問題の特性を活用して中間思考ステップを設計および分解します。表1に示されるように、異なる問題によって、思考はいくつかの単語(クロスワード)、1行の方程式(24のゲーム)、または文章計画の段落全体(クリエイティブライティング)になることがあります。これは、質問をいくつかのタスクに分割する方法と似ています。各タスクは私たちが議論するステップZnです。この部分は、質問をタスクに分解するだけのものです。計画のようなものであり、実際にはこの部分で何の思考も行いません。
![参考文献[10]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*lQUGig2RwBH8OcabkocyoA.png)
2. 思考生成:思考分解の各ステップにタスクを定義した後、実際に思考を生成します。与えられたステップZnに対して、k個の思考候補を生成しようとします。思考を生成する方法は2つあります:サンプルと提案。
a. CoTプロンプトからi.i.d.思考をサンプルします。生成プロセスをk回独立に繰り返します。思考空間が豊富な場合(例:各思考が段落である場合)や、i.i.d.サンプルが多様性をもたらす場合には、これがより良く機能します。
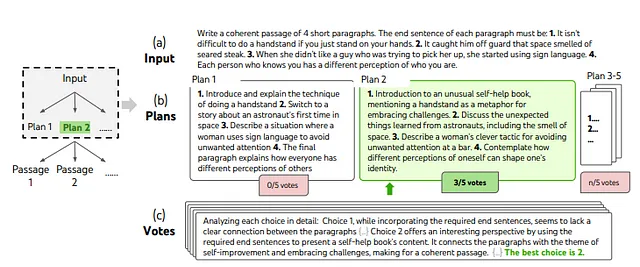
上記の図では、ランダムに選択されたクリエイティブライティングのタスクの熟考された探索のステップが示されています。入力が与えられると、言語モデルは異なるプランを5つサンプルし、その後5回投票して最良のプランを決定します。過半数の選択肢は、同じサンプル-投票手順で出力パッセージの作成に使用されます。
b.「提案プロンプト」を使用して思考を順次提案します。思考空間が制約されている場合(例:各思考が単語または行である場合)、同じ文脈で異なる思考を提案することで重複を回避するのに適しています。ここでは、1回の推論でk個の思考を生成します。したがって、これらのk個の思考は独立しているとは限りません。
3. 状態の評価:この部分では、状態評価関数v(s)を定義します。木を展開するために、この関数を使用して良いパスを見つけます。チェスプログラミングのように、木の与えられたパスs=[x, z1…i]を評価します。評価関数を定義する方法は2つあります:
- 各状態を独立して評価する:各状態’s’(またはパス)は独立して評価されます。[例:24のゲーム]
- 状態全体で投票する:全ての状態’S’が与えられた場合、各状態’s’は状態の一貫性(COT)のように他の状態と比較して評価されます。[例:クリエイティブライティングのタスク]
例:24のゲーム
24のゲームは数学的な推論のチャレンジであり、目標は4つの数字と基本的な算術演算(+-*/)を使用して24を得ることです。例えば、入力「4 9 10 13」が与えられた場合、解の出力は「(10–4) * (13–9) = 24」になります。
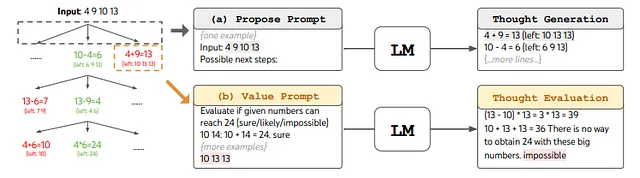
‘Game of 24’をToTにフレームするために、思考を中間方程式に分解します。上記の図(a)に示されているように、各ツリーノードで「左」の数値を抽出し、LMにいくつかの可能な次のステップを提案するように促します。同じ「提案プロンプト」が3つの思考ステップすべてに使用されますが、4つの入力数値の例しか持っていません。ToTでは幅優先探索(BFS)を実行し、各ステップで最良のb = 5個の候補を保持します。ToTで熟考されたBFSを実行するためには、図(b)に示されているように、LMに各思考候補を24に到達するための「確実/可能性がある/不可能」として評価させます。目的は、少ない先読み試行で判定できる正しい部分解を促進し、「大きすぎる/小さすぎる」といった常識に基づく不可能な部分解を除外し、「可能性がある」残りの部分解を保持することです。各思考について3回値をサンプルします。
4. 検索アルゴリズム:ツリーを拡張しようとします。各葉ノードに対して、状態評価関数で評価します。どの葉ノードを評価するかを選ぶために、検索アルゴリズムを使用します。幅優先探索や深さ優先探索のような検索アルゴリズムを使用することができます。ツリーの構造に応じて異なる検索アルゴリズムをプラグインして使用することができます。
概念的には、ToTはLMを用いた一般的な問題解決方法としていくつかの利点があります:
- 汎用性:IO、CoT、CoT-SC、および自己改善は、ToTの特殊な場合と見なすことができます(つまり、限られた深さと幅のツリー)
- モジュール性:基本的なLMだけでなく、思考の分解、生成、評価、および検索手順をすべて独立して変更することができます。
- 適応性:異なる問題の特性、LMの能力、およびリソース制約を受け入れることができます。
- 利便性:追加のトレーニングは必要ありません。事前にトレーニングされたLMが十分です。
ToTフレームワークは、LMにより自律的かつ知的に意思決定し、問題を解決する力を与えます。
制限事項:ToTはタスクのパフォーマンスを向上させるためにサンプリング手法よりも多くのリソース(例:モデルAPIのコスト)を必要としますが、ToTのモジュラーな柔軟性により、ユーザーはそのようなパフォーマンスとコストのトレードオフをカスタマイズすることができます。また、進行中のオープンソースの取り組みにより、将来的にはそのようなコストも軽減されるでしょう。
自動プロンプト技術
プロンプトエンジニアリングは経験的な科学であり、プロンプトエンジニアリングの方法の効果はモデル間で大きく異なるため、試行錯誤やヒューリスティックが必要です。プロンプトエンジニアリングのプロセスを自動化することは可能でしょうか?これは活発な研究分野であり、以下のセクションでは自動プロンプト設計のアプローチについていくつか議論します。
自動プロンプトの増強と選択 COT
論文「ラベル付きデータからのChain-of-Thoughtを用いた自動プロンプトの増強と選択」[11]では、ほとんどのCoTの研究は、人間によって設計された合理的なチェーンをプロンプトとして言語モデルに与えることに依存しています。しかし、ラベル付きのトレーニングデータが人間によって注釈付けされていない実世界のアプリケーションでは、チェーン・オブ・ソートを自動的に構築することは困難です。著者らは、増強-剪定-選択という3つのステッププロセスを提案しています:
- 増強:少数ショットまたはゼロショットのCoTプロンプトを使用して、質問から複数の擬似思考チェーンを生成します。
- 剪定:生成された回答が正解と一致するかどうかに基づいて、擬似チェーンを剪定します。
- 選択:選択された例に対して、分散減少ポリシーグラディエント戦略を適用して、選択された例の確率分布を学習します。ポリシーとしての例の確率分布と報酬としての検証セットの正確性を考慮します。
Auto-CoT:自動チェーン・オブ・ソートのプロンプト
「大規模言語モデルにおける自動チェーン・オブ・ソートのプロンプト」[12]では、著者らは質問と推論チェーンを自動的に構築するためのAuto-CoTパラダイムを提案しています。この技術では、クラスタリング技術を利用して質問をサンプリングし、チェーンを生成します。著者らは、LLMが特定のタイプの間違いをする傾向があることを観察しました。ある種のエラーは埋め込み空間で類似しており、それにより同じグループにまとめられます。頻繁なエラークラスターから1つまたは少数のサンプルのみをサンプリングすることで、1つのエラータイプの間違ったデモが多すぎるのを防ぎ、多様な例のセットを収集することができます。
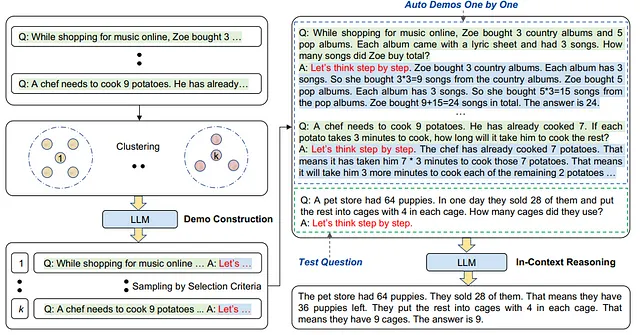
Auto-CoTは次の主要なステージで構成されています:
- 質問のクラスタリング:与えられた質問セットQに対してクラスター分析を実行します。まず、Sentence-BERTによってQの各質問に対するベクトル表現を計算します。文脈を考慮したベクトルは固定サイズの質問表現を形成するために平均化されます。次に、質問表現はk-meansクラスタリングアルゴリズムによって処理され、k個の質問クラスターが生成されます。
- デモンストレーションの選択:各クラスターから代表的な質問のセットを選択します。各クラスター内のサンプルはクラスターの重心に対する距離でソートされ、重心に近いものが最初に選択されます。
- 根拠の生成:選択された質問に対して、ゼロショットのCoTを使用して推論のチェーンを生成し、few-shotプロンプトを構築して推論を実行します。
LLMはCoTの促進による推論能力を示しています。Manual-CoTの優れたパフォーマンスは、デモンストレーションの手作りにかかっています。このような手動の設計を排除するために、提案されたAuto-CoTは自動的にデモンストレーションを構築します。多様性を持つ質問をサンプリングし、推論チェーンを生成してデモンストレーションを構築します。推論データセット上の実験結果は、GPT-3を使用した場合、Auto-CoTが手動デザインのデモンストレーションを必要とするCoTパラダイムのパフォーマンスを一貫して一致または上回ることを示しました。
結論
コンテキスト学習またはプロンプティングは、LLMとのコミュニケーションを支援し、望ましい結果を得るためにその動作を誘導するのに役立ちます。大量のオフライントレーニングセットは必要ありませんし、モデルへのオフラインアクセスも必要ありません。また、非エンジニアにとっても直感的に理解しやすい方法です。プロンプティングエンジニアリングは、プロンプティングを信頼性のある機能の構築手法として活用することを目指しています。それは経験的な科学であり、プロンプティングエンジニアリングの効果はモデルによって大きく異なるため、重い実験とヒューリスティクスが必要です。プロンプティングには、新しいデータセットに適応するために、人間の努力が必要です。注釈付けプロセスは非常に難しく、質問を選択するだけでなく、各質問の推論ステップを注意深く設計する必要があるため、プロンプティング技術の自動化が必要です。
参考文献
[1] 大規模言語モデルの調査、https://arxiv.org/pdf/2303.18223.pdf
[2] コンテキスト学習の調査、https://arxiv.org/pdf/2301.00234.pdf
[3] 大規模言語モデルの新たな能力、https://arxiv.org/pdf/2206.07682.pdf
[4] GPTはなぜコンテキストで学習できるのか?言語モデルはメタオプティマイザとして勾配降下を暗黙的に行う、https://arxiv.org/pdf/2212.10559.pdf
[5] コンテキスト学習の説明、暗黙のベイズ推論として、http://ai.stanford.edu/blog/understanding-incontext/
[6] Chain-of-Thoughtプロンプティングは大規模言語モデルで推論を引き出す、https://arxiv.org/pdf/2201.11903.pdf
[7] 大規模言語モデルはゼロショットの推論エンジンです、https://arxiv.org/pdf/2205.11916.pdf
[8] コンテキスト学習と帰納ヘッド。Transformer Circuits, 2022. https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html .
[9] 自己整合性はLLMの推論チェーンの理解を向上させる、https://arxiv.org/pdf/2203.11171.pdf
[10] 思考の木、https://arxiv.org/pdf/2305.10601.pdf
[11] ラベル付きデータからのChain-of-Thoughtを使用した自動プロンプト増強と選択、https://arxiv.org/pdf/2302.12822.pdf
[12] 大規模言語モデルにおける自動Chain-of-Thoughtプロンプティング、https://arxiv.org/pdf/2210.03493.pdf
[13] 大規模言語モデルは自己改善できる、https://www.arxiv-vanity.com/papers/2210.11610/
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Webスケールトレーニング解放:DeepMindがOWLv2とOWL-STを紹介、未知語彙物体検出の革新的ツール、前例のない自己学習技術によって駆動されます
- 製造品の品質におけるコンピュータビジョンの欠陥検出を、Amazon SageMaker Canvasを使用したノーコード機械学習で民主化する
- エンタープライズAIとは何ですか?
- DORSalとは 3Dシーンの生成とオブジェクトレベルの編集のための3D構造拡散モデル
- Hugging FaceとGradioを使用して、5分でAIチャットボットを構築する
- LOMO(LOw-Memory Optimization)をご紹介します:メモリ使用量を削減するために、勾配計算とパラメータの更新を1つのステップで融合する新しいAIオプティマイザです
- デバイス上での条件付きテキストから画像生成のための拡散プラグイン