データ駆動型のディスパッチ
データ駆動型のディスパッチ' -> 'データ駆動型ディスパッチ
シカゴの車の衝突に対するサービス呼出しを予測するための教師あり学習の使用
はじめに
今日の高速な世界では、ディスパッチ応答システムにおけるデータに基づく意思決定の必要性がますます重要になっています。ディスパッチャーは、通話を聞く際に、重症度や時間の感度などの要素に基づいてケースを優先順位付けします。教師あり学習モデルのパワーを活用することで、このプロセスを最適化する可能性があります。これにより、人間のディスパッチャーの評価と連携して、ケースの重症度をより正確に予測することができます。
この記事では、シカゴの車の衝突から負傷者や重大な車両の損傷を予測するために開発したソリューションの1つを紹介します。衝突場所、道路状況、速度制限、発生時刻などの要素を考慮して、単純な「この車の衝突には救急車またはレッカー車が必要か?」という質問に答えるためです。
要するに、この機械学習ツールの主な目的は、他の既知の要素に基づいて最もおそらく呼び出しが必要な衝突を分類することです(医療、レッカー、またはその両方)。このツールを活用することで、応答者は天候や時刻などのさまざまな条件に基づいて、都市のさまざまな地域に効率的にリソースを割り当てることができます。
このようなツールが正確かつ効果的になるためには、歴史的なデータから予測を行うための大規模なデータソースが必要です。幸いにも、シカゴ市は既にそのようなリソース(シカゴデータポータル)を持っているので、このデータをテストケースとして使用します。
- 「Salesforce Data Cloudを使用して、Amazon SageMakerで独自のAIを持ち込む」
- 「Amazon SageMakerとSalesforce Data Cloudの統合を使用して、SalesforceアプリをAI/MLで強化しましょう」
- 「データサイエンスの仕事にバイアスが満ちた状態になる6つの信念」
このような予測モデルを実装することで、都市の道路での衝突に対処する際の準備と対応時間の効率が確実に向上するでしょう。衝突データ内の潜在的なパターンとトレンドにおいて理解を深めることで、より安全な道路環境の形成と緊急サービスの最適化に取り組むことができます。
以下では、データのクリーニング、モデルの構築、微調整、評価の詳細について説明し、モデルの結果を分析し、結論を導きます。このプロジェクトのGitHubフォルダへのリンク(Jupyterノートブックとプロジェクトのより詳細なレポートが含まれています)はこちらから見つけることができます。
データの収集と準備
初期設定
以下はプロジェクトで使用された基本的なデータ分析ライブラリのリストです。pandasやnumpyのような標準的なライブラリに加えて、可視化のためにmatplotlibのpyplotとseabornも使用しました。また、データフレームを使用するデータサイエンスプロジェクトには、欠損データを可視化するためのmissingnoライブラリも使用しました:
#generic data analysis import osimport pandas as pdfrom datetime import dateimport matplotlib.pyplot as pltimport numpy as npimport seaborn as snsimport missingno as msno機械学習モジュールSciKit learn(sklearn)からの関数は、機械学習エンジンを構築するためにインポートされました。ここでは以下にこれらの関数を示します。分類モデルのセクションでこれらの関数の目的を説明します:
#Preprocessingfrom sklearn.preprocessing import LabelEncoderfrom sklearn.preprocessing import StandardScaler# Modelsfrom sklearn.neighbors import KNeighborsClassifier# Reportingfrom sklearn.model_selection import train_test_splitfrom sklearn.model_selection import RandomizedSearchCV#metricsfrom sklearn.metrics import accuracy_scorefrom sklearn.metrics import f1_scorefrom sklearn.metrics import precision_scorefrom sklearn.metrics import recall_scoreこのプロジェクトのデータは、以下の2つのソースからすべてシカゴデータポータルからインポートされました:
- 交通事故:シカゴ地域の車両衝突のライブデータセットです。このデータセットの特徴は、衝突時の条件(天候条件、道路の配置、緯度経度データなど)です。
- 警察ビート境界:CPDビートの境界を示す静的なデータセットです。このデータセットは、交通事故データセットに地区情報を補完するために使用されます。最も頻繁な衝突が発生する地区での分析を実行するために元のデータセットに結合することができます。
データのクリーニング
両方のデータセットをインポートしたら、最終的な分析に地区データを追加するためにマージすることができます。これは、pandasの.merge()関数を使用して行われます。私は両方のデータフレームで内部結合を使用し、両方の情報をキャプチャするため、両方のデータでビートデータを結合キーとして使用しました(交通事故データセットではbeat_of_occurrenceとしてリストされ、警察ビートデータセットではBEAT_NUMとしてリストされます):
#衝突データをビートデータに結合 - 内部結合collisions = collision_raw.merge(beat_data, how='inner', left_on='beat_of_occurrence', right_on='BEAT_NUM' ).info()関数から提供される情報を簡単に見ると、スパースなデータを含む多くの列があることがわかります。これは、missingno行列関数を使用して視覚化することができます:
#欠損データの可視化#報告受信日による値のソートcollisions = collisions.sort_values(by='crash_date', ascending=True)#欠損データの行列のプロットmsno.matrix(collisions)plt.show()#ソートされたデータの情報を表示print(collisions.info())これにより、すべての列の欠損データの行列が表示されます:
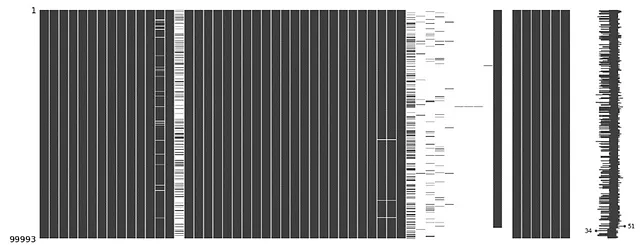
スパースなデータを含む列を削除することで、よりクリーンなデータセットを抽出することができます。削除する列はリストで定義され、.drop()関数を使用してデータセットから削除されます:
#不要な列を定義するdrop_cols = ['location', 'crash_date_est_i','report_type', 'intersection_related_i', 'hit_and_run_i', 'photos_taken_i', 'crash_date_est_i', 'injuries_unknown', 'private_property_i', 'statements_taken_i', 'dooring_i', 'work_zone_i', 'work_zone_type', 'workers_present_i','lane_cnt','the_geom','rd_no', 'SECTOR','BEAT','BEAT_NUM']#列を削除するcollisions=collisions.drop(columns=drop_cols)#欠損データの行列のプロットmsno.matrix(collisions)plt.show()#ソートされたデータの情報を表示print(collisions.info())これにより、よりクリーンなmsno行列が得られます:
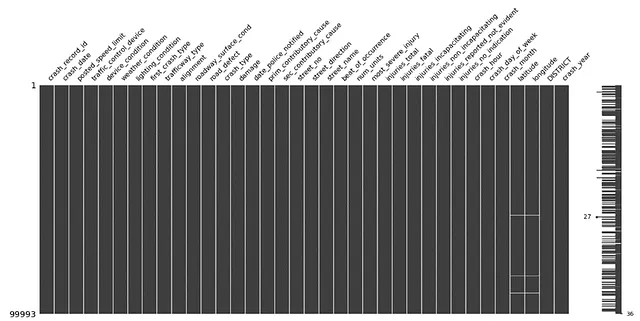
緯度と経度のデータを見ると、一部の行にはヌル値があり、他の行には誤ってゼロ値が含まれていました(おそらく報告のエラーです):
これらはモデルのトレーニング中にエラーを引き起こす可能性があるため、それらを削除しました:
#不正確な緯度/経度データ - これらの行を削除するcollisions = collisions[collisions['longitude']<-80]collisions = collisions[collisions['latitude']>40]データが適切にクリーニングされたので、分類モデルの開発に進むことができました。
分類モデル
探索的データ分析
機械学習モデルに進む前に、いくつかの探索的データ分析(EDA)を実行する必要があります。データフレームの各列は、データの分布を示すために50のビンでヒストグラムにプロットされます。ヒストグラムは、データ分布の概要を示すだけでなく、外れ値を特定するのにも役立ち、最終的には特徴エンジニアリングの決定にも役立ちます:
#数値値のヒストグラムのプロットcollisions.hist(bins=50,figsize=(16,12))plt.show()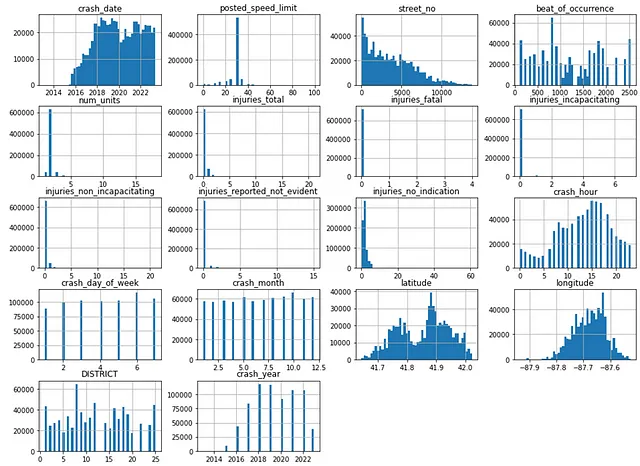
列のヒストグラムを一見すると、緯度データは二峰性であり、経度データは右に偏っています。これを標準化する必要があります。これにより、機械学習の目的により適用できるようにします。
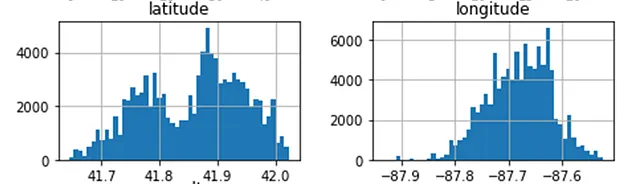
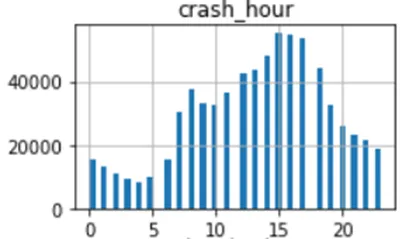
さらに、クラッシュ時間の列は周期的な性質を持っているようです。これは三角関数(例えば、サイン)を使用して変換することができます。
スケーリングと変換
スケーリングは、データ前処理で使用されるテクニックであり、特徴量を標準化して類似の大きさにします。これは機械学習モデルにとって特に重要です。なぜなら、モデルは一般的に入力特徴量のスケールに敏感だからです。このモデルでは、StandardScaler()関数をスケーラーとして定義しました。このスケーリング関数は、データを平均0、標準偏差1に変換します。
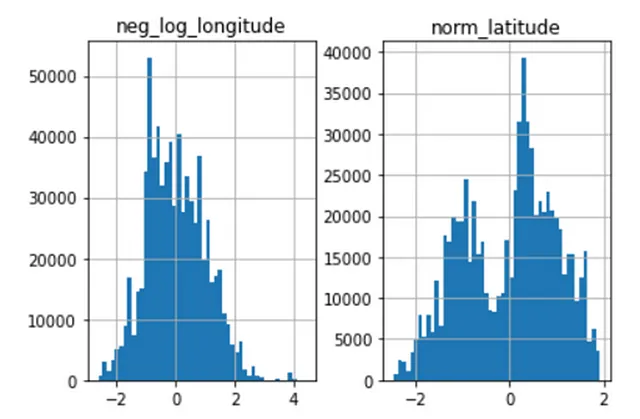
スケベ度の高いデータや二峰性の分布を持つデータの場合、対数関数を使用してスケーリングすることができます。対数関数は、スケベ度の高いデータをより対称にし、データの裾を縮小します。これは外れ値との扱いに便利です。このように緯度と経度のデータをスケーリングしました。経度データはすべて負の値ですので、負の対数を計算してからスケーリングしました。
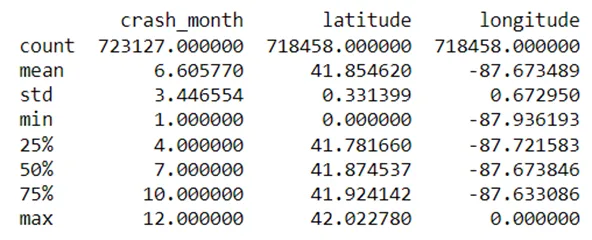
#緯度と経度のデータをスケーリングdatascaler = StandardScaler()# 経度の対数変換collisions_ml['neg_log_longitude'] = scaler.fit_transform(np.log1p(-collisions_ml['longitude']). values.reshape(-1,1))# 緯度の正規化collisions_ml['norm_latitude'] = scaler.fit_transform(np.log1p(collisions['latitude']). values.reshape(-1, 1))これにより、以下のような効果が生じます:
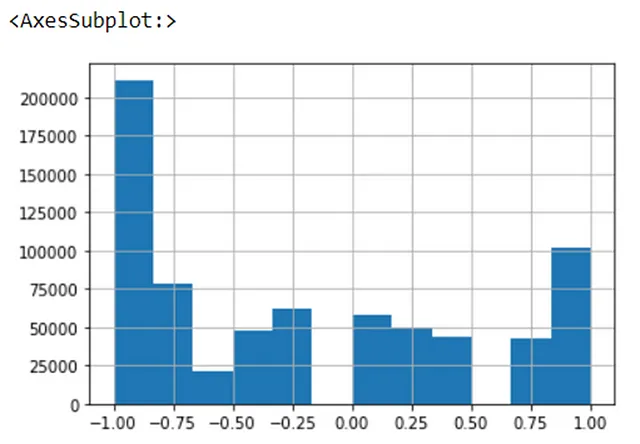
比較すると、周期性のあるデータは通常、サインやコサインなどの三角関数を使用してスケーリングされます。クラッシュ時間データは以前の観察に基づいておおよそ周期的に見えるため、以下のようにデータにサイン関数を適用しました。numpyのsin()関数はラジアンであるため、入力をラジアンに変換してからサインを計算しました:
#クラッシュ時間の変換 #データは周期的であり、三角関数変換を使用してエンコードできる#三角関数変換 - sin(クラッシュ時間)collisions_ml['sin_hr'] = np.sin(2*np.pi*collisions_ml['crash_hour']/24)変換されたデータのヒストグラムは以下の通りです:
最後に、モデルからスケーリングされていないデータを削除し、モデルの予測に干渉しないようにしました:
#以前の緯度/経度の列を削除lat_long_drop_cols = ['longitude','latitude']collisions_ml.drop(lat_long_drop_cols,axis=1,inplace=True)#クラッシュ時間の列を削除collisions_ml.drop('crash_hour',axis=1,inplace=True)データエンコーディング
データ前処理における別の重要なステップはデータのエンコーディングです。これは非数値データ(例えばカテゴリ)を数値形式で表現し、機械学習アルゴリズムと互換性のある形式にするための手法です。このモデルでは、ラベルエンコーディングと呼ばれる方法を使用してカテゴリデータを処理しました。列の各カテゴリには、モデルに入力する前に数値が割り当てられます。このプロセスのダイアグラムは以下の通りです:
データセットの列をエンコードしました。最初に、元のデータセットから保持したい列を分割し、データフレームのコピー(collisions_ml)を作成しました。次に、カテゴリカルな列をリストで定義し、sklearnのLabelEncoder()関数を使用してカテゴリカルな列をフィットして変換しました:
#列をリストに分割
ml_cols = ['posted_speed_limit','traffic_control_device', 'device_condition', 'weather_condition',
'lighting_condition', 'first_crash_type', 'trafficway_type','alignment',
'roadway_surface_cond', 'road_defect', 'crash_type','damage','prim_contributory_cause',
'sec_contributory_cause','street_direction','num_units', 'DISTRICT',
'crash_hour','crash_day_of_week','latitude', 'longitude']
cat_cols = ['traffic_control_device', 'device_condition', 'weather_condition', 'DISTRICT',
'lighting_condition', 'first_crash_type', 'trafficway_type','alignment',
'roadway_surface_cond', 'road_defect', 'crash_type','damage','prim_contributory_cause',
'sec_contributory_cause','street_direction','num_units']
#データセットのコピーを作成
collisions_ml = collisions[ml_cols].copy()
#カテゴリカルな値をエンコード
label_encoder = LabelEncoder()
for col in collisions_ml[cat_cols].columns:
collisions_ml[col] = label_encoder.fit_transform(collisions_ml[col])データが十分に前処理されたので、データをトレーニングデータとテストデータに分割し、分類モデルをデータに適合させることができます。
トレーニングデータとテストデータの分割
機械学習モデルを構築する際には、データをトレーニングセットとテストセットに分けることが重要です。トレーニングセットは、モデルを正しい応答で学習するために使用される初期データの一部であり、テストセットはモデルのパフォーマンスを評価するために使用されます。これらを別々に保持することは、過学習やモデルのバイアスのリスクを減らすために必要です。
drop()関数を使用してcrash_type列を抽出しました(残りの特徴量はcrash_typeを予測するための変数として使用されます)し、モデルで予測する結果としてcrash_typeを定義しました。sklearnのtrain_test_split関数を使用して、初期データの20%をトレーニングデータとし、残りをモデルのテストに使用しました。
#テストセットの作成
#Xとyの値を設定
X = collisions_ml.drop('crash_type', axis=1)
y = collisions_ml['crash_type']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)K最近傍法分類
このプロジェクトでは、K最近傍法(KNN)分類モデルを使用して特徴量から結果を予測します。KNNモデルは、未知のデータポイントの周囲のK個の既知の値の値をチェックし、それらの「近傍」ポイントの値に基づいてデータポイントを分類します。これはパラメトリックでない分類器であり、基になるデータ分布についての仮定を行いません。ただし、計算コストが高く、データの外れ値に敏感であるという欠点があります。
トレーニングデータに対して初期のn_neighborsを3としてKNN分類器をインスタンス化し、モデルをトレーニングデータに適合させました:
#分類器 - K最近傍法
#KNN分類器のインスタンス化
KNNClassifier = KNeighborsClassifier(n_neighbors=3, metric='euclidean')
KNNClassifier.fit(X_train, y_train)トレーニングデータにモデルを適合させた後、以下のようにテストデータに対して予測を行いました:
#予測
#トレーニングセットで予測
y_train_pred = KNNClassifier.predict(X_train)
#テストデータで予測
y_test_pred = KNNClassifier.predict(X_test)評価
機械学習モデルの評価は、通常、4つの指標で行われます。正解率、適合率、再現率、F1スコアです。これらの指標の違いは非常に微妙ですが、平易な言葉で以下のように定義できます:
- 正解率:モデルの予測のうち、真陽性の予測の割合。通常、トレーニングデータとテストデータの両方の正解率を測定してモデルの適合性を評価する必要があります。
- 適合率:モデルの陽性予測のうち、真陽性の予測の割合。
- 再現率:データセット内の陽性ケースのうち、真陽性の予測の割合。
- F1スコア:モデルがデータ内の陽性インスタンスをどの程度正確に識別できるかを示す総合的な指標であり、適合率と再現率のスコアを組み合わせたものです。
以下のコードスニペットを使用して、KNNモデルのメトリックを計算しました。また、トレーニングセットとテストセットのモデルの正確性の差を計算し、適合性を評価しました。
#モデルの評価# モデルの正確性を計算する# トレーニングデータのモデルの正確性を計算するtrain_accuracy = accuracy_score(y_train, y_train_pred)# テストデータのモデルの正確性を計算するtest_accuracy = accuracy_score(y_test, y_test_pred)# f1スコア、適合率、再現率を計算するf1 = f1_score(y_test, y_test_pred)precision = precision_score(y_test,y_test_pred)recall = recall_score(y_test,y_test_pred)# パフォーマンスの比較print("トレーニングの正確性:", train_accuracy)print("テストの正確性:", test_accuracy)print("トレーニング-テストの正確性の差:", train_accuracy-test_accuracy)# 適合率スコアを出力するprint("適合率スコア:", precision)# 再現率スコアを出力するprint("再現率スコア:", recall)# f1スコアを出力するprint("F1スコア:", f1)KNNモデルの初期メトリックは以下の通りです:

モデルはテストの正確性(79.6%)、適合率(82.1%)、再現率(91.1%)、およびF1スコア(86.3%)で高いスコアを叩き出しました。しかし、テストの正確性はトレーニングの正確性の93.1%よりもはるかに高く、13.5%の差があります。これは、モデルがデータに過剰適合していることを示しており、未知のデータに対して正確な予測を行うのが難しいことを意味します。したがって、モデルをより適合性のあるものに調整する必要があります。これは、ハイパーパラメータの調整というプロセスを使用して行うことができます。
ハイパーパラメータの調整
ハイパーパラメータの調整とは、機械学習モデルの最適なハイパーパラメータのセットを選択するプロセスです。私はk-foldクロスバリデーションを使用してモデルを調整しました。これは、データをk個のサブセット(またはフォールド)に分割し、各フォールドを検証セットとして使用し、残りのデータをトレーニングセットとして使用するリサンプリング技術です。この方法は、特定のトレーニング/テストセットの選択によってモデルにバイアスが導入されるリスクを減らすのに効果的です。
KNNモデルのハイパーパラメータは、近傍の数(n_neighbors)と距離メトリックです。KNN分類器で距離を測定する方法はいくつかありますが、ここでは次の2つのオプションに焦点を当てました:
- ユークリッド距離:2点間の直線距離と考えることができます。これは最も一般的に使用される距離メトリックです。
- マンハッタン距離:または「シティブロック」距離とも呼ばれ、2点の座標の絶対値の差の合計です。都市の建物の隅に立って、反対の隅に行こうとしていると想像してみてください。建物を横切って反対側に行くのではなく、ブロックを1つ上り、ブロックを1つ横切ります。
注意すべきは、重みパラメータ(すべての近傍が同じ重みで投票するか、より近い近傍により重要性が与えられるかを決定するもの)も調整できたが、重み付けを均一に保つことにしたということです。
n_neighborsを3、7、10、およびユークリッドまたはマンハッタンのメトリックで定義したパラメータグリッドを作成しました。その後、KNN分類器を推定器としてランダムサーチCVアルゴリズムをインスタンス化し、パラメータグリッドを渡しました。cvパラメータを5に設定することで、データを5つのフォールドに分割するようにアルゴリズムを設定し、トレーニングセットに適合させました。以下に、これに関するコードのスニペットを示します:
#ハイパーパラメータの調整(RandomizedSearchCV)# パラメータグリッドの定義param_grid = { 'n_neighbors': [3, 7, 10], 'metric': ['euclidean','manhattan']}# ランダムサーチCVをインスタンス化random_search = RandomizedSearchCV(estimator=KNeighborsClassifier(), param_distributions=param_grid, cv=5)# トレーニングデータに適合させるrandom_search.fit(X_train, y_train)# 最良のモデルとパフォーマンスを取得best_classifier = random_search.best_estimator_best_accuracy = random_search.best_score_print("最高の正確性:", best_accuracy)print("最良のモデル:", best_classifier)アルゴリズムから最高の正確性と分類器が取得され、分類器はn_neighborsを10に設定し、マンハッタン距離メトリックを使用する場合に最も優れたパフォーマンスを発揮し、正確性スコアは74.0%になります:

そのようにしてこれらのパラメーターが分類器に入力され、モデルが再トレーニングされました:
#分類器-K最近傍法#KNN分類器をインスタンス化KNNClassifier = KNeighborsClassifier(n_neighbors=10, metric = 'manhattan')KNNClassifier.fit(X_train,y_train)性能メトリックスは、前と同じ方法で分類器から再度抽出されました-このイテレーションのメトリックスのスクリーンショットは以下で確認できます:
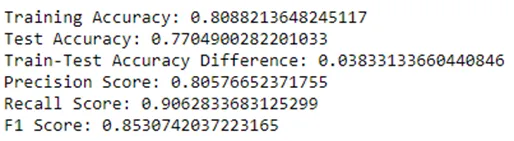
交差検証により、すべてのメトリックスの結果がわずかに悪化しました。テストの正確性が2.6%、精度が1.5%、再現率が0.5%、F1スコアが1%減少しました。ただし、訓練とテストの正確性の差は3.8%に減少し、最初は13.5%でした。これにより、モデルがデータに過剰適合していないことが示され、未知のデータの予測により適しています。
結論
要約すると、KNN分類器は、衝突がレッカー車や救急車を必要とするかを予測するのに優れた性能を発揮しました。最初のイテレーションのモデルからの初期のメトリックスは印象的でしたが、テストと訓練の正確性の差は過剰適合を示していました。ハイパーパラメータのチューニングにより、モデルを最適化することができ、2つのデータセット間の正確性の差が大幅に減少しました。このプロセス中に性能メトリックスがわずかに悪化しましたが、適合性が改善されたモデルの利点はこれらの懸念を上回ります。
参考文献
- Levy, J. (n.d.). Traffic Crashes — Crashes [データセット]. Retrieved from Chicago Data Portal. Available at: https://data.cityofchicago.org/Transportation/Traffic-Crashes-Crashes/85ca-t3if (Accessed: 14th May 2023).
- Chicago Police Department. (n.d.). Boundaries — Police Beats (current) [データセット]. Retrieved from Chicago Data Portal. Available at: https://data.cityofchicago.org/Public-Safety/Boundaries-Police-Beats-current-/aerh-rz74 (Accessed: 14th May 2023).
- Zach M. (2022). “How to Perform Label Encoding in Python (With Example).” [オンライン]. Available at: https://www.statology.org/label-encoding-in-python/ (Accessed: July 19th, 2023).
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
